Data Abstract Schemas
Schemas are one of the most powerful features in Data Abstract, and a big part of what sets it apart from other multi-tier frameworks.
Simply put, a schema is a file that defines the set of data tables that a multi-tier application works with. It defines their structure and relationships and how they relate to the actual data stored in the back-end database(s).
What sounds like a simple concept opens up Data Abstract for many powerful capabilities, so let's take a step back and look at schemas in more detail.
Traditional Middle Tier Data Access
One of the core features of any multi-tier database project is to access data from back-end database systems, provide that data to clients and apply changes made by clients back to the database.
In most multi-tier frameworks, including ADO.NET or Delphi's DataSnap, data access is handled directly by the middle tier, usually by dropping components for individual datasets, configuring them with the proper SQL statements, etc. Any business rules code written for the middle tier will usually directly interface with these components.
This couples the middle tier (and with it, the entire solution) very tightly to the underlying database. Changes in database structure require manual changes in the components and the configured SQL statements; switching database systems altogether is often impossible without virtually recreating the middle tier from scratch.
Schemas
In Data Abstract, schemas clearly separate the middle- and client-tier code from the actual data access. The schema defines the set of tables that the application accesses, and both client and middle tier will code against the data structure as defined in the schema – which is independent of any specific database format.
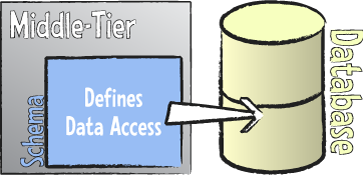
In addition to defining data tables and their fields, the schema also maintains how these data tables map to actual physical tables in the back-end database. This can (and in many cases will) be a 1:1 mapping, with tables defined in the schema corresponding directly to tables in the database, but it doesn't need to be.
The schema also contains all the information needed by Data Abstract to retrieve data or perform updates, so this entire process can be handled under the hood by the Data Abstract library, without involving or requiring user code.
Benefits of Schemas
Benefits of the schema architecture described above include the following:
- Abstraction of user code (on client and middle tier) from actual data access.
- All user code is database agnostic.
- Data access and updates can be handled completely by the library.
- No SQL code needs to be written and maintained (unless you want to).
- Application can be changed to use different back-end database types without code changes.
- Application can be adapted to database changes by only adjusting the schema.
- Easy access to different database systems from the same code base.
- RAD Schema Modeler™ application for designing and maintaining schemas.
Let's explore some of these points in more detail:
Abstraction of User Code from Data Access
As already outlined above, in a typical Data Abstract application, all code is written to talk to the data tables as defined in the schema. The code does not need to know what database system is used on the back-end, how to generate SQL code to talk to that database, or what data access components are needed.
Compare this to ADO.NET, where components need to be dropped that are specific to – say – SQL Server and contain (whether hand written or wizard generated) SQL strings. If you later want to target an Oracle backend instead of (or in addition to) SQL Server, none of these can be reused. Similar concepts apply to DataSnap or other third party solutions on the Delphi side.
In contrast, Data Abstract middle-tier code does not need to care (and in most cases will not even know) what type of database it is talking to and what low level data access components or providers might be involved in the actual communication with the database. If user code is involved at all (and in many cases there is no need for that), it uses classes provided by the Data Abstract library that abstract this away.
All User Code is Database Agnostic
Because a Data Abstract middle tier does not know or care about these things, the same application can run against any variety of data base systems, with only making minimal (if any) adjustments in the schema. In many cases, simply defining a new connection string will suffice to target a different database type.
Data Access is Handled by the Library, No SQL Code Needs to Be Written
The Data Abstract library handles all retrieval and updates of data. Because the schema contains all information that maps the data tables to the underlying database, Data Abstract can generate the necessary SELECT, INSERT, UPDATE and DELETE SQL statements on the fly whenever it needs to fetch data or update it.
The library (or the individual database drivers) know about varying SQL dialects and can, where needed, generate different SQL based on the database type. It can also account for field or table names that might differ between back end and schema.
Of course this does not mean that a Data Abstract middle tier must rely on auto-generated SQL code. Schemas can contain customized or fine-tuned SQL for data retrieval and updates, and they provide flexible options for providing different custom SQL code for different databases, where needed.
Applications Can be Changed to Use Different Back-End Database Types
For these same reasons, Data Abstract makes it very easy to switch database types on the fly. Because none of the code written is tied to or knows about one particular database type, but uses the abstracted data tables from the schema, changing database vendors can be as easy as defining a new connection string or – in more complex scenarios – making some additional adjustments in the schema to account for differences in the databases.
No user code needs to be changed, unless it explicitly and purposely contained database-vendor specific code.
Applications Can be Adapted to Database Changes
Because schemas provide an abstraction layer on top of the structure of the physical database, applications can easily be adjusted to database changes by merely adjusting mappings in the schema. For example, simple changes such as the renaming of a field or table can be applied in the schema – the application code never has to change to use the new names; the application will work as it is.
This can not only save work for updating the application code, but can also relieve the need to deploy new client applications to all users for these changes.
Access to Different Database Systems from the Same Code Base
Even more powerful than the idea of easily switching between database types (or structures) is the concept of using the same code base to talk to different databases simultaneously. Because Schemas can have explicit support for different connections and mappings at the same time, a schema can be designed so that the same application can be deployed against different databases, without even recompiling. One customer might run your middle-tier server against Oracle, while another uses DB2 or Microsoft SQL Server.
It is also possible to support more than one back-end database in a single running server instance – one client might be working on data from one database, while another accesses a second database of different type or structure.
This also makes it very easy to migrate up from legacy databases; a middle-tier server might be written to talk to an old CRM database that is in production, while the database administrator is migrating data to a new, better structured, database. End-users could access both the old and new database until the migration is complete.
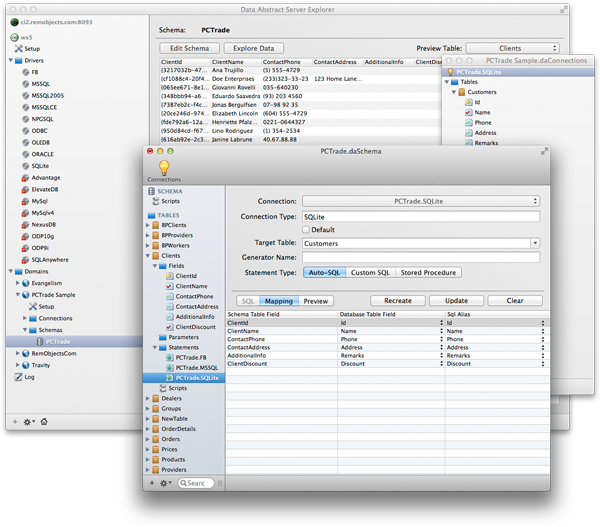
Schema Modeler for Designing Schemas
Because schemas are such an important pillar of the Data Abstract architecture, the Schema Modeler application is provided to allow developers or database architects to define and design schemas in a RAD way that is intuitive to use.
Schema Modeler integrates deeply with the supported IDEs, but can also be used stand-alone by non-developers. It is available for Windows and Mac. More details about Schema Modeler can be found in the Documentation, here.
Thank you!
Your message has been sent, and someone will get back to you soon, usually within a business day.
For technical or support questions, please also check out our RemObjects Talk support forum, as well as out other Support Options.
Data Abstract is a product of
RemObjects Software.
This Website is copyright RemObjects Software 2002-2024. All rights reserved.
Legal.
Data Abstract™, Relativity™,
Remoting SDK™, and other product names and corresponding logos are
trademarks
or registered trademarks of RemObjects Software, LLC.
![]()
![]() This site is proudly powered by Data Abstract and the Elements™ compiler.
This site is proudly powered by Data Abstract and the Elements™ compiler.
